

懒人采集器电脑版是一款非常好用的网页采集软件,它拥有内置浏览器,能够以可视化的方式帮助用户采集各种网页内容。懒人采集器电脑版操作方便简单,不需要掌握任何专业的网络知识,只需点击鼠标就能轻松创建采集任务,有需要的用户敬请下载。
懒人采集器电脑版特色功能
1、软件操作简单,可通过鼠标点击的方式轻松选取要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化后的火狐浏览器,加上独创的内存优化使浏览器采集也可以高速运行,甚至可以快速转换为HTTP方式运行,享受更高的采集速度!而在抓取JSON数据时,同样可以使用浏览器可视化方式,通过鼠标点选需要抓取的内容,完全不需要去分析JSON数据结构,使非网页专业设计人士也可以轻松抓取需要的数据;
3、不用分析网页请求和源代码,却支持更多的网页采集;
4、先进的智能算法,可以一键生成目标元素XPATH、自动识别网页列表、自动识别分页中的下一页按钮……
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导的方式简单映射字段,即可轻松导出到目标网站数据库中。
懒人采集器电脑版安装指南
下载并解压完成后,双击setup1.0.exe启动安装程序(1.0是版本后,后续新版会不同)
按照安装向导,一路点击“下一步”按钮即可完成安装。
懒人采集器电脑版使用教程
第一步:设置起始网址
要采集一个网站的数据,首先我们要设置从哪些网址进入采集,比如我们要采集一个网站的国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,而一般不会设置网站首页为起始网址,因为首页通常会包含很多列表,比如最新文章、热门文章、推荐文章等等各种列表块,并且这些列表块里显示的内容也是非常有限的,采集这些列表的话一般都无法采集完整信息。
下面我们以采集新浪新闻为例,从新浪首页找到国内新闻,但该栏目首页内容还是比较杂乱,而且还细分三个子栏目
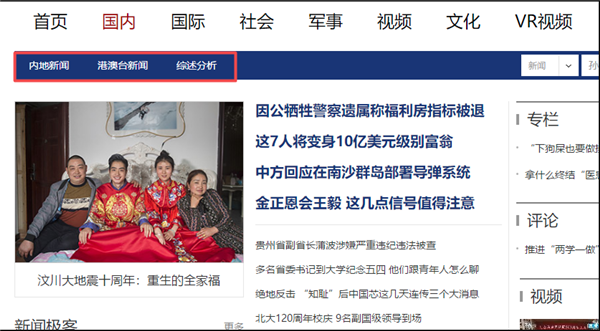
我们从进入其中一个子栏目“内地新闻”看一下
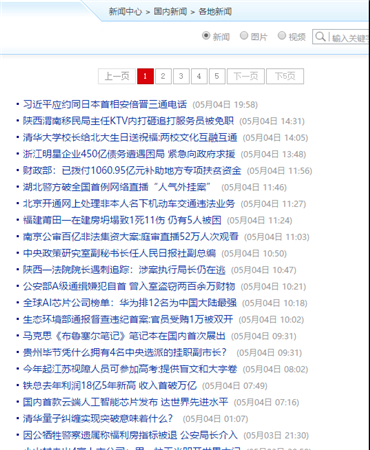
该栏目页包含有一个带分页的内容列表,通过切换分页,我们就可以采集到该栏目下的所有文章,所以这种列表页就非常适合作为我们采集的起始网址。
现在,我们就复制该列表网址到任务编辑框第一步的文本框中
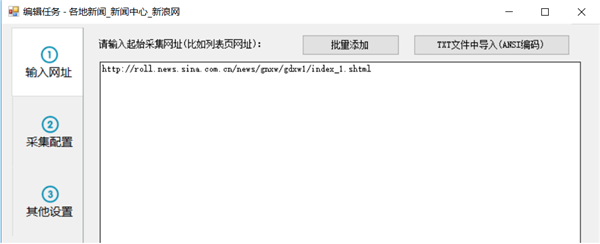
如果你要在一个任务中同时采集国内新闻里的其他子栏目,也可以把另两个子栏目列表地址复制进来,因为这些子栏目列表格式都是相似的。但为了便于导出或发布分类数据,一般不建议多个栏目内容混合在一起。
对于起始网址我们也可以批量添加或从txt文件导入,比如我们要采集前5页,也可以这样自定义五个起始页
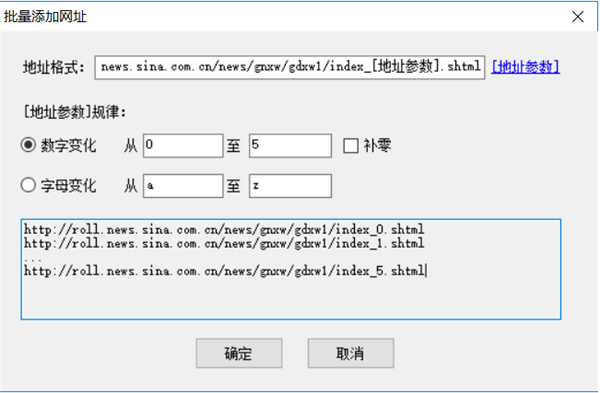
需要注意的是如果这里自定义了多个分页列表,在后面的采集配置里就不要再启用分页了,通常我们要采集某个栏目下的所有文章时,都只需要定义该栏目第一页为起始网址就行了,在后面的采集配置里启用分页,就可以采集到每个分页列表的数据。
第二步:① 自动生成列表和字段
进入第二步后,对于某些网页,懒人采集器会智能分析出该页的列表,并自动高亮选择网页列表和生成列表数据,如
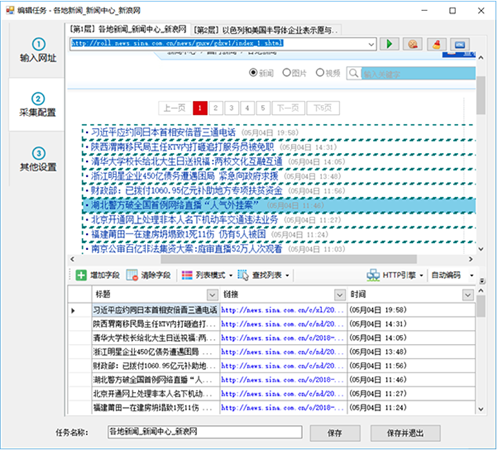
然后我们再对这些数据进行修整,比如删掉一些不需要的字段
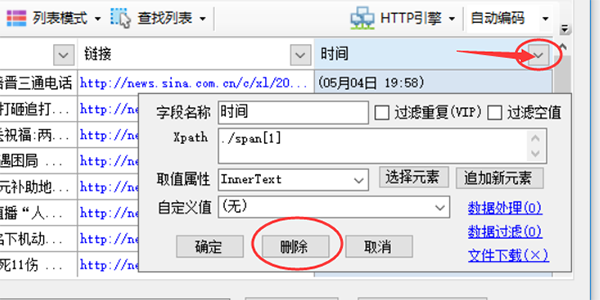
点击图示三角符号,会弹出该字段采集详细配置,点击上面的删按钮即可删除该字段,其余参数后面章节会独立介绍。
如果某些网页自动生成的列表数据并不是我们想要的数据,可以点击“清除字段”,把生成的字段全部清除。
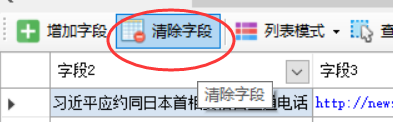
如果自动分析出的高亮列表也不是我们要采集的列表,那么我们就手动选取列表。要是想取消高亮显示的列表框,可以点击 查找列表 - 列表XPATH,把里面的xpath清空后确定即可。
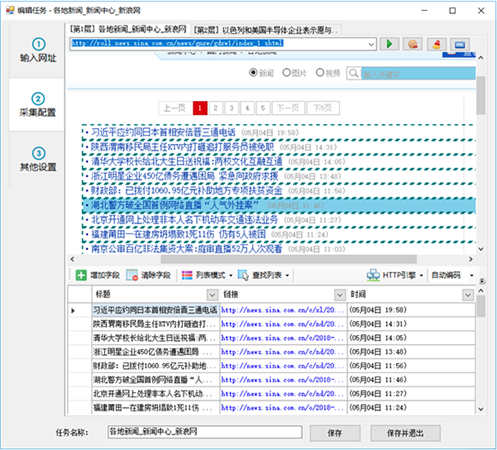
第二步:② 手动生成列表
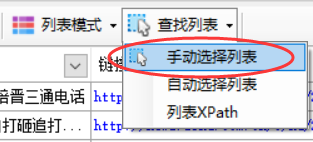
点击“查找列表”按钮,选择“手动选择列表”
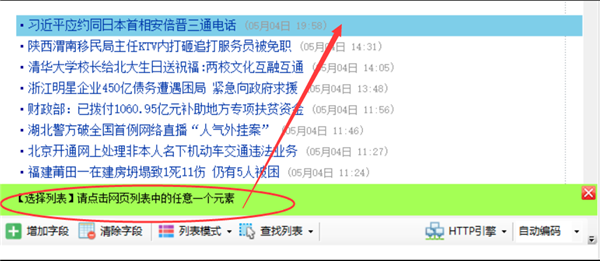
按提示,用鼠标左键点击网页列表中的第一行数据
点完第一行,再按提示点击第二行或其他相似的行
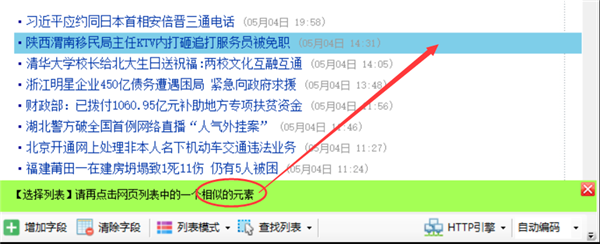
点击完列表里的任意两行后,整个列表就高亮显示出来了,同时该列表里的字段也会字段生成,如果生成的字段不对,点击清除字段,把下面的字段全部清除掉,下一章再介绍手动选取字段。
第二步:③ 手动生成字段
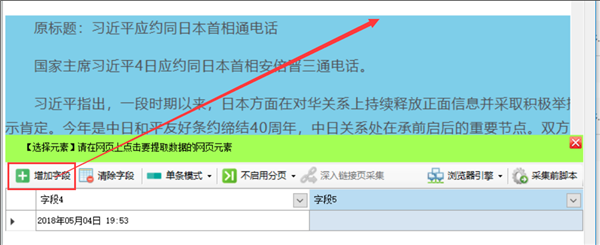
点击“增加字段”按钮
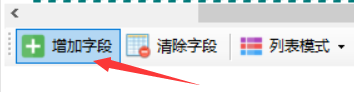
点击列表中任意一行中要提取的元素,比如要提取标题和链接地址,鼠标左键点击一下该标题即可
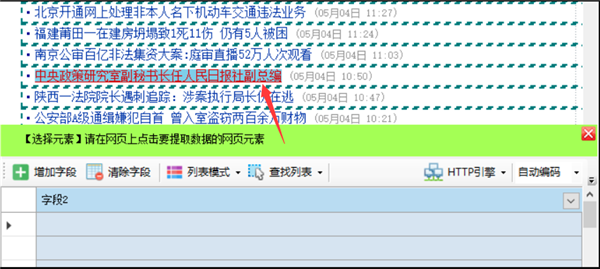
当点击的是网页链接时,会提示是否用时要抓取链接地址
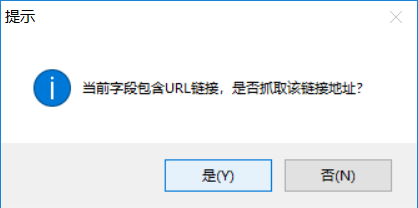
如果要同时提取链接标题和链接地址,点“是”,如果只要提取标题文本,点否,这里我们点“是”
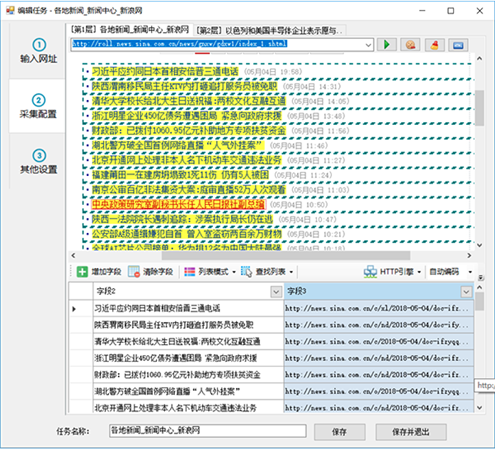
系统会自动生成标题和链接地址字段,并在字段列表中显示出提取到的字段内容,当点击底部表格字段标题时,会在网页上以黄色背景高亮显示出匹配的内容。
如何还有标记列表中的其他字段,点击新增字段,重复以上操作即可。
第二步:④ 分页设置
当列表有分页时,启用分页后就可以采集到所有的分页列表数据。
网页分页有两种
普通分页:存在分页条,并显示有“下一页”按钮,点击后可以进入下一页,如之前的新浪新闻列表里的分页
瀑布流分页:网页滚动条拉到底部时会自动加载下一页内容
如果是普通分页,我们选择尝试自动设置或手动设置
自动设置分页
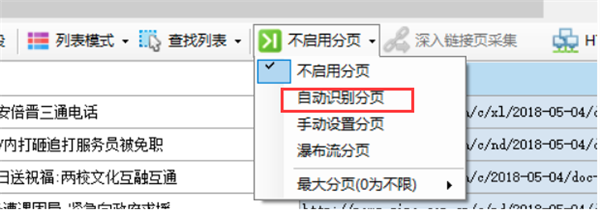
新建任务时默认是没有启用分页的,点击“不启用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出对话框提示“成功识别并设置了分页元素!”,并在网页“下一页”按钮上出现高亮的红色虚线框(部分网页按钮可能不会显示虚线框),至此成功启用自动分页
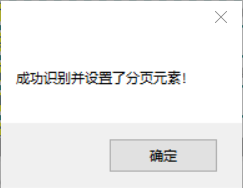
如果自动识别识别,会出现如下绿色提示框

手动设置分页
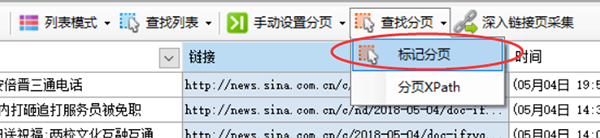
在菜单中选择“手动设置分页”
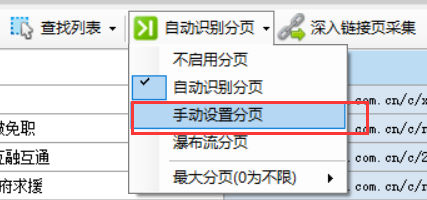
然后会自动出现“查找分页”按钮,点击后弹出菜单,选择“标记分页”
按提示向导点击“下一页”按钮
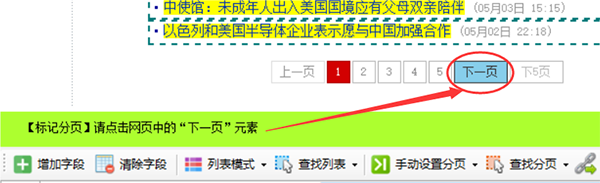
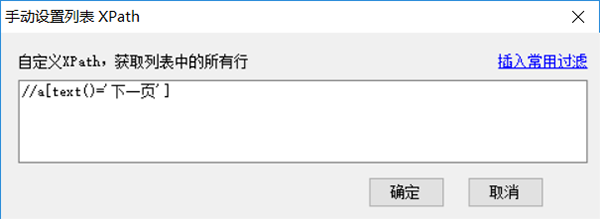
点击后会在网页“下一页”按钮上出现高亮的红色虚线框(部分网页按钮可能不会显示虚线框),至此成功标记了分页,如果要查看刚才设置的分页xpath,可以选择菜单中的“分页XPath”,即可看到该分页xpath,在这里也可以手动输入xpath进行设置。
瀑布流分页
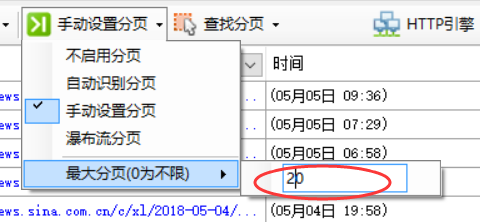
有些网页需要将滚动条拉到底部才能进入下一页,例如今日头条、知乎等网站,在菜单中选择瀑布流分页即可启用该分页。使用瀑布流分页采集时,页面会自动滚动到底部,直到分页完成或达到指定的分页次数。
最大分页
指定最大分页次数,也就是切换分页的次数不会超过此数值。
第二步:⑤ 采集内容页等多级网页
如果我们要采集二级页面,如内容页,或采集更深一级的页面,三级、四级等,在当前页字段列表中,必须包含有一个提取链接地址的字段,也就是提取属性为Href的字段,如图
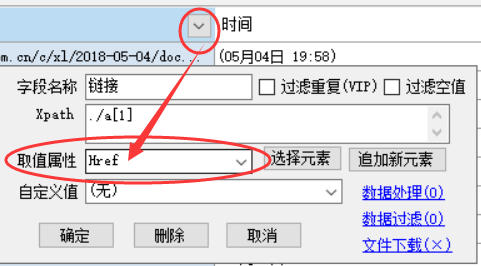
点击该字段标题栏,选中该列后会出现“深入链接页采集”按钮
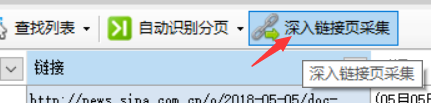
点击该按钮后会自动创建一个配置选项卡,并自动打开之前选中那个字段的一个网址。

而采集模式也自动显示为“单条模式”
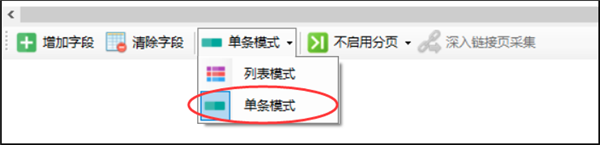
列表模式:用于提取某个网页列表中的数据,预览中可看到多条数据
单条模式:适用于采集内容详情页里的各项信息,如文章标题、时间、正文等
因为我们深入采集的这个页面是内容页,所有使用默认的“单条模式”
然后,我们新建一个字段,提取网页中的文章发布时间,因为文章标题在第一层列表采集里已经提取了,这里就不需要重复了,采集运行时,多个页面的字段会自动合并为一个表格数据的。
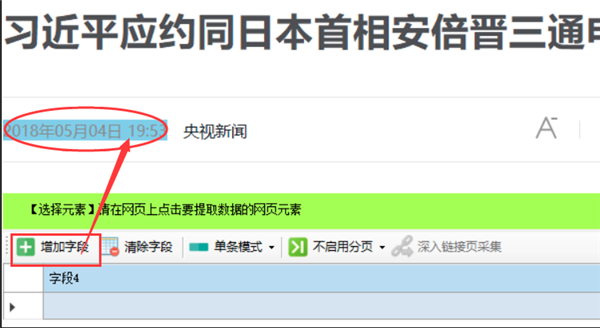
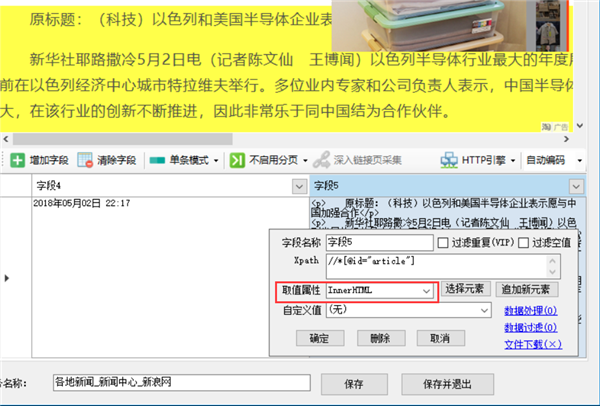
继续新建字段提取正文
而为了保持原文的段落格式,这里的取值属性可以选择InnerHtml,即该字段提取的数据包含Html标签
第二步:其他设置
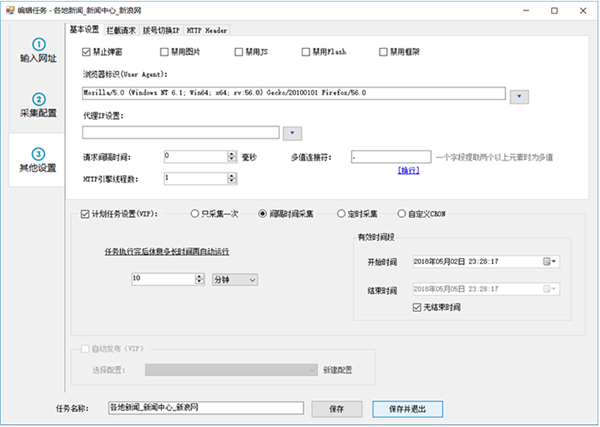
在第三步的基本设置里,我们可以对浏览器做一些设置,比如禁用图片、JS、Flash、框架等,提高浏览网页的速度。
还可以设置浏览器标识(UserAgent)、代理IP、请求的间隔时间等
浏览器标识(UserAgent):网页通过读取浏览器标识来获取客户端的一些信息
请求间隔时间:用于降低请求的频率,即降低采集速度,避免因采集太快而被封IP,如果不需要降速,可以设置为0时
多值连接符:字段设置了多个xpah提取多个元素时,使用这里自定义的连接符连接多个元素值
HTTP引擎线程数:使用HTTP请求时,多线程运行的线程数,同一个HTTP请求的任务可以拆分并使用多个线程同时采集,提高采集速度,只适用于HTTP引擎,浏览器引擎不适合。
-
 69.3MB 简体中文 2021-08-08
69.3MB 简体中文 2021-08-08 -
 69.5MB 简体中文 2021-06-05
69.5MB 简体中文 2021-06-05 -
 35.42MB 简体中文 2021-05-05
35.42MB 简体中文 2021-05-05 -
 35.42MB 简体中文 2021-04-06
35.42MB 简体中文 2021-04-06













- 精选留言 来自安徽铜陵联通用户 发表于: 2023-10-22
- 楼主你真好!太谢谢你了
- 精选留言 来自江西赣州电信用户 发表于: 2023-2-13
- 没有可比性,效率高了不止一点
- 精选留言 来自江苏苏州联通用户 发表于: 2023-9-8
- 不错不错。。。
- 精选留言 来自山东枣庄电信用户 发表于: 2023-3-16
- 毋庸置疑的好软件,买就完事了
- 精选留言 来自江西新余电信用户 发表于: 2023-2-7
- 刚好在找这个新版本































 浙公网安备 33038202002266号
浙公网安备 33038202002266号