

DeepFaceLab特别版是一款使用起来非常简单的智能AI换脸软件,我们在编辑视频的时候,可以直接通过Deepfacelab中文版将视频中其他人的脸进行更换,加入自己想要的人脸图片,并且这款软件还可以让人脸的契合度达到最高程度,看不出任何修改的痕迹哦!

DeepFaceLab特别版软件简介
Deepfacelab2.0中文版是一款非常简单实用的AI换脸软件,用户通过这款软件可以将自己的脸更换到自己爱豆的视频或图片上去,这样一来仿佛使得用户与爱豆一起参演电影以及共同合影一般,非常有意思。该软件采用了傻瓜式的操作方法,相信用户可以轻松上手。
Deepfacelab最新版是一款非常有意思的AI智能换脸软件,用户无需掌握任何编程知识便可以对视频、图片进行一键换脸操作并且契合度非常高,看不出任何一点瑕疵。另外,该软件的配置略高需要搭配GTX1080以上显卡,所以用户在使用之前注意升级自己电脑配置。

软件特色
1、可单独使用,具有零依赖性,可与所有Windows版本的预备二进制文件(CUDA,OpenCL,ffmpeg等)一起使用。
2、新型号(H64,H128,DF,LIAEF128,SAE,恶棍)从原始的facewap模型扩展而来。
3、新架构,易于模型试验。
4、适用于2GB旧卡,如GT730。在18小时内使用2GB gtx850m笔记本电脑进行深度训练的示例
5、面部数据嵌入在png文件中(不再需要对齐文件)。
6、通过选择最佳GPU自动管理GPU。
7、新预览窗口
8、提取器和转换器并行。
9、为所有阶段添加了调试选项。
10、多种面部提取模式,包括S3FD,MTCNN,dlib或手动提取。
11、以16的增量训练任何分辨率。由于优化设置,使用NVIDIA卡轻松训练256。
DeepFaceLab特别版软件功能
1、安装方便,环境依赖几乎为零,下载打包 app 解压即可运行(最大优势)
2、添加了很多新的模型
3、新架构,易于模型实验
4、人脸图片使用 JPG 保存,节省空间提高效率
5、CPU 模式,第 8 代 Intel 核心能够在 2 天内完成 H64 模型的训练。
6、全新的预览窗口,便于观察。
7、并行提取
8、并行转换
9、所有阶段都可以使用 DEBUG 选项
10、支持 MTCNN,DLIBCNN,S3FD 等多种提取器
11、支持手动提取,更精确的脸部区域,更好的结果。
DeepFaceLab特别版使用教程
workspace目录下的文件,先了解下
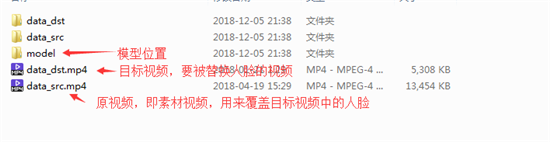
1. 我们看到下面目录,可以看到都是批处理,这里我已经翻译成中文啦,非常好理解。我们双击它1)批处理,输入y之后,就会清理了,不需要清理就不用执行了。
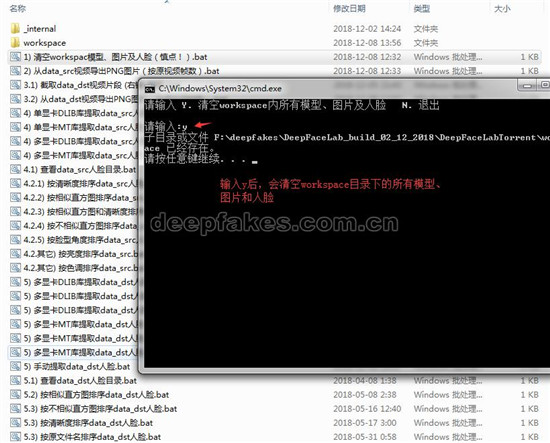
2. 第二步,我们提取data_src视频,这里我们按照原视频帧数进行分解(如果要指定帧数,可以右击编辑)
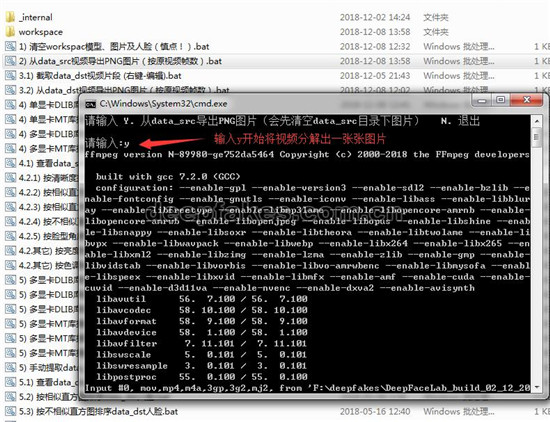
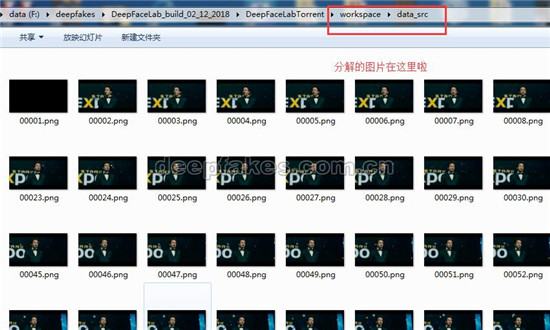
分解完之后,我们打开workspace/data_src目录,可以看到分解出的图片
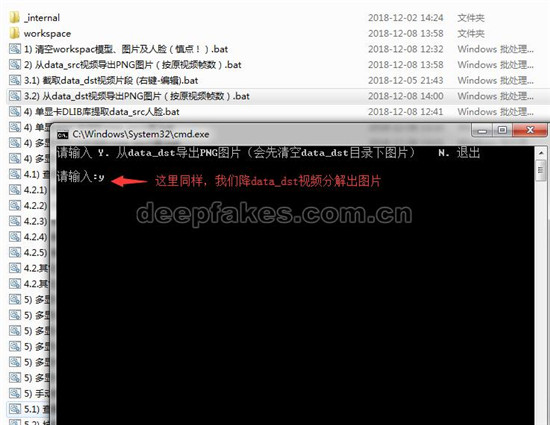
3. 同样的,我们将data_dst视频分解出图片,执行批处理
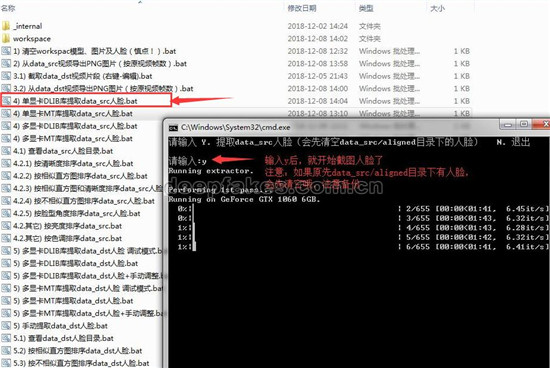
4. 分解出图片知道后,我们要图片中的人脸提取出来,先从data_src开始,我们用DLIB库提取人脸,双击 4) 单显卡DLIB库提取data_src人脸
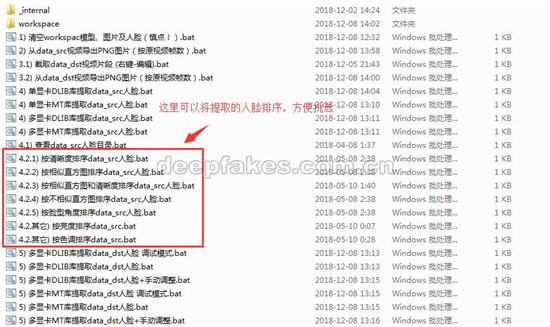
提取好data_src的人脸之后,我们看到下面的批处理是排序,有兴趣的同学可以自己逐个执行看效果,这里我们跳过。
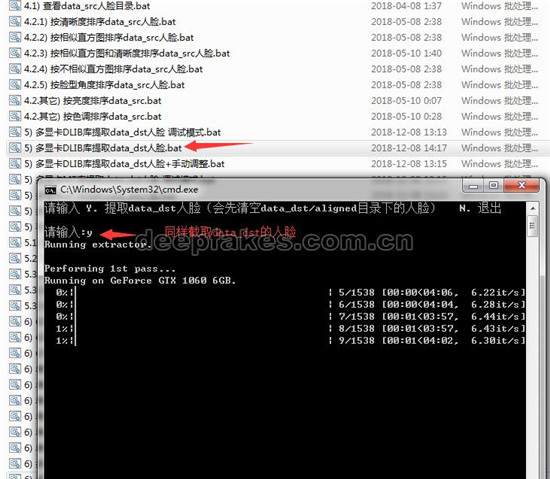
5.同样的,我们需要提取data_dst的人脸,这里我们也用DLIB来提取人脸,执行批处理开始
一、人脸素材需要多少?
DST:尽量不要少,因为它是有限的且需要被替换的素材
SRC:根据各软件的脸图筛选规则和网上大神的建议,总体来说,SRC脸图最好是大概700~3999的数量,像Deepfacelab的作者,他就认为1500张够了。对于SRC,各种角度、各种表情、各种光照下的内容越多越好,很接近的素材没有用,会增加训练负担。
二、 手动对齐识别人脸模式如何使用?
回车键:应用当前选择区域并跳转到下一个未识别到人脸的帧
空格键:跳转到下一个未识别到人脸的帧
鼠标滚轮:识别区域框,上滚放大下滚缩小
逗号和句号(要把输入法切换到英文):上一帧下一帧
Q:跳过该模式
老实说,这个功能极其难用,画面还放得死大……
三、MODEL是个什么东西?
MODEL是根据各种线条或其他奇怪的数据经过人工智能呈现的随机产生的假数据,就像PS填充里的“智能识别”
你可以从https://affinelayer.com/pixsrv/ 这个网站里体验一下什么叫MODEL造假
四、MODEL使用哪种算法好?
各有千秋,一般Deepfacelab使用H128就好了,其他算法可以看官方在GitHub上写的介绍:https://github.com/iperov/DeepFaceLab
五、Batch Size是什么?要设置多大?
Batch Size的意思大概就是一批训练多少个图片素材,一般设置为2的倍数。数字越大越需要更多显存,但是由于处理内容更多,迭代频率会降低。一般情况在Deepfacelab中,不需要手动设置,它会默认设置显卡适配的最大值。
根据网上的内容和本人实际测试,在我们这种64和128尺寸换脸的操作中,越大越好,因为最合理的值目前远超所有民用显卡可承受的范围。
六、MODEL训练过,还可以再次换素材使用吗?
换DST素材:
可以!而且非常建议重复使用。
新建的MODEL大概10小时以上会有较好的结果,之后换其他DST素材,仅需0.5~3小时就会有很好的结果了,前提是SRC素材不能换人。
换SRC素材,那么就需要考虑一下了:
第一种方案:MODEL重复用,不管换DST还是换SRC,就是所有人脸的内容都会被放进MODEL进行训练,结果是训练很快,但是越杂乱的训练后越觉得导出不太像SRC的脸。
第二种方案:新建MODEL重新来(也就是专人专MODEL)这种操作请先把MODEL剪切出去并文件夹分类,这种操作可以合成比较像SRC的情况,但是每次要重新10小时会很累。
第三种方案:结合前两种,先把MODEL练出轮廓后,再复制出来,每个MODEL每个SRC脸专用就好了。
其、合成图连接成视频后发现部分画面面部颤抖怎么办?
把DST视频通过其他软件放大些尺寸再重新进行操作。因为逻辑上分析,扩大了画面后,软件识别偏移的步长比例会小一些。
-
 1.8GB 简体中文 2022-02-18
1.8GB 简体中文 2022-02-18 -
 1.81GB 简体中文 2021-08-18
1.81GB 简体中文 2021-08-18 -
 1.81GB 简体中文 2021-09-15
1.81GB 简体中文 2021-09-15












- 精选留言 来自湖北襄阳移动用户 发表于: 2023-2-1
- 就信任和喜欢咱们这个网站。
- 精选留言 来自福建漳州移动用户 发表于: 2023-5-15
- 登峰造极,绝世之作。
- 精选留言 来自江西景德镇移动用户 发表于: 2023-1-16
- 超越品质的软件,不愧久负盛名
- 精选留言 来自新疆哈密电信用户 发表于: 2023-8-1
- 心累,总算是更新到最新正式版了,之前遇到的问题希望已经解决了
- 精选留言 来自黑龙江牡丹江移动用户 发表于: 2023-8-7
- 非常喜欢啊,23333,且下且珍惜。
































 浙公网安备 33038202002266号
浙公网安备 33038202002266号