

Stata17破解版是一款使用起来非常简单方便的多功能数据分析软件,Stata17破解版百度云不仅为用户们提供了傻瓜式的操作步骤,让用户们快速掌握使用技巧。同时Stata17中文版还可以支持直方图、箱线图、等高线图、散点图矩阵等多种不同图表的制作,功能非常强大。
Stata17破解版软件简介
Stata17破解版百度云是一款功能强大、简单实用的多功能数据分析软件,这款软件采用了极其人性化的操作界面并且还能够为用户提供傻瓜式的操作步骤,相关用户在这里可以非常轻松的进行数据分析、数据管理以及图表绘制等一系列操作,这样就能够有效的提升了相关用户的操作效率。
Stata17中文破解版是一款Stata软件的最新版本。这款软件在基于原版操作方式的基础上有了极大的提升,比如说:优化了软件界面、提升了软件速度以及加入了双重差分法的官方命令、久期数据的新命令并且还整合了Python、Java等等等,这样就能够有效的简化繁琐的数据分析流程。
Stata17破解版软件特色
1. 表格 (Tables)
用户一直希望我们提供更完美的表格,现在您可以很容易地创建比较回归结果或汇总统计数据的表格,您可以创建样式并将其应用于您构建的任何表,还可以将表导出到MS Word?, PDF, HTML, LaTeX, MS Excel?, 并将它们插入到报告中。新版本修改了table命令,新的 collective 前缀可以从任意多个命令收集任意多的结果,生成表格,并将其导出为多种格式等。您还可以使用新的Tables Builder来单击并创建表格。
2. 贝叶斯计量经济学
Stata能进行计量经济学,也能进行贝叶斯统计,现在Stata能够进行贝叶斯计量经济学!想要用概率性的陈述来回答经济问题,例如:那些参加职业培训项目的人在未来五年里更有可能保持就业吗?想把对经济过程的先验知识结合起来吗?Stata新推出的贝叶斯计量经济学功能可以帮到您。适合许多贝叶斯模型,如横截面模型、面板数据模型、多层模型和时间序列模型。使用贝叶斯因子比较模型,获取更多预测和展望!
在计量经济学建模中使用贝叶斯方法的吸引力之一是将关于通常在实践中可用的模型参数的外部信息纳入其中。这些信息可能来自历史数据,也可能自然来自经济过程的知识。无论哪种方式,贝叶斯方法都可以使我们将外部信息与我们在当前数据中观察到的信息结合起来,以形成对感兴趣的经济过程的更现实的看法。
Stata 17 在贝叶斯计量经济学领域提供了几个新功能:
> Bayesian VAR models /贝叶斯VAR模型
> Bayesian IRF and FEVD analysis /贝叶斯IRF和FEVD分析
> Bayesian dynamic forecasting /贝叶斯动态预测
> Bayesian longitudinal/panel-data models /贝叶斯纵向/面板数据模型
> Bayesian linear and nonlinear DSGE models /贝叶斯线性与非线性DSGE模型
3. 更快的Stata
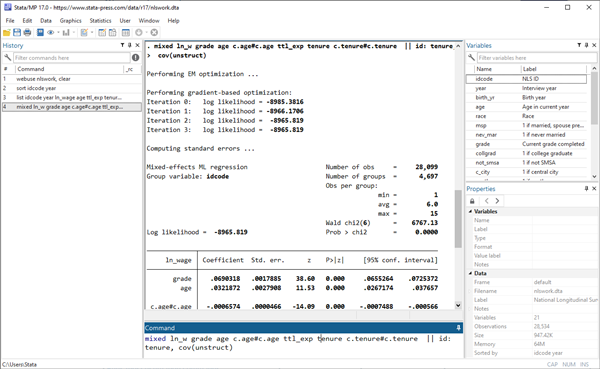
Stata不仅重视数据处理的准确性而且重视处理的速度,两者之间通常需要权衡取舍,但Stata努力为用户提供两全其美的选择。在Stata 17中,我们更新了sort和collapse的算法,使这些命令运行更快。我们还对某些估计命令(例如mixed)实现了速度改进,使这些命令适合多层混合效应模型(multilevel mixed-effects models)。
4. 双重差分(DID)和DDD模型
新的估计命令didregress和xtdidregress具有使用重复测量数据拟合双重差分(DID)模型和三重差分(DDD)模型。 didregress适用于重复横截面数据,xtdidregress适用于纵向/面板数据。
采用DID和DDD模型,用重复测量数据估计平均治疗效果(ATET)。 治疗效果可以是药物方案对血压的影响,也可以是培训计划对就业的影响。 与现有的teffects命令可用的标准横截面分析不同,DID分析可控制估计ATET时的组和时间效应,组可在其中识别重复的度量。DDD分析控件可控制其他组效果及其与时间的相互作用——您最多可以指定三个组变量或两个组变量和一个时间变量。
5. 区间删失Cox模型
半参数Cox比例风险回归模型通常用于分析未删失和右删失的事件时间数据。 新的估计命令stintcox可使用Cox模型,来估计删失事件时间数据。当未直接观察到发生某个事件(例如癌症复发)的时间,但已知该时间间隔在某个时间间隔内时,便会进行时间间隔检查。例如,可以在定期检查之间检测到癌症的复发,但是无法观察到确切的复发时间。我们只知道在先前检查和当前检查之间的某个时间复发了癌症。忽略区间删失可能会导致错误的结果(有偏差的)。
当没有完全指定基线风险函数时,对区间删失事件时间数据进行半参数估计是一项挑战,因为没有一个事件时间是被精确地观测到的。
因此,这些数据的“半参数”建模通常采用样条方法或分段指数模型作为基线风险函数。直到最近的方法学进展(在stintcox命令中实现)之后,才提供真正的区间删失事件时间数据的半参数建模。
6. 多维元分析
您想分析多项研究的结果。这些研究报告了多个效应量,这些效应量很可能在一项研究中相互关联。单独的meta分析(例如使用现有meta命令的那些meta分析)将忽略相关性。现在,您可以使用新的meta mvregress命令执行多维元分析,这将解释相关性。
7. 贝叶斯VAR模型
贝叶斯前缀现在支持var命令以拟合贝叶斯矢量自回归(VAR)模型。VAR模型通过将结果变量的滞后时间作为模型预测变量来研究多个时间序列之间的关系。已知这些模型具有许多参数:对于K个结果变量和标记,至少存在p(K ^ 2 + \ nn1)个参数。对模型参数的可靠估计可能会遇到挑战,尤其是在使用小型数据集的情况下。贝叶斯VAR模型通过整合有关模型参数的先验信息来稳定参数估计,从而克服了这些挑战。
8. PyStata
Stata 17引入了一个我们称之为PyStata的概念。PyStata是一个涵盖了Stata和Python可以交互的所有方式的术语。
Stata 16具有从Stata调用Python代码的功能。Stata 17允许您通过一个新的pystata Python包从一个独立的Python环境中调用Stata,从而极大地扩展了此功能。您可以在基于IPython内核的环境(例如Jupyter Notebook和控制台以及Jupyter Lab和控制台)中方便地访问Stata和Mata。
在其他支持IPython内核的环境中(例如,Spyder IDE和PyCharm IDE);或从命令行访问Python(例如Windows命令提示符,macOS终端,Unix终端和Python的IDLE)时。
9. Lasso治疗效果评估
您可以使用teffects 来估计治疗效果。您可以使用Lasso来控制许多协变量。(当我们说“很多”时,可以理解为成百上千甚至更多!)现在,您可以使用telasso来估计治疗效果并控制许多协变量。
10. Galbraith图
新命令meta galbraithplot生成Galbraith图以进行元分析。这些图可用于评估研究的异质性和检测潜在的异常值。当有许多研究时,它们还可以用作森林图forest plots的替代方案,以总结元分析结果。
11. 留一元分析
现在,您可以通过使用meta summarize和meta forestplot的新选项leaoneout来执行留一元分析。留一元分析通过在每次分析中排除一项研究来执行多种元分析。研究通常会产生夸大的效应大小,这可能会扭曲整体结果。留一元分析可用于研究每项研究对总体效应量估计的影响,并确定有影响力的研究。
12. 贝叶斯纵向/面板模型
通过使用xtreg表示连续结果,xtlogit或xtprobit表示二进制结果,xtologit或xtoprobit表示序数结果等,可以拟合随机效应面板数据模型。在Stata 17中,您可以简单地通过在它们前面加上Bayes前缀来拟合这些模型的Bayesian版本。
13. 面板多项逻辑模型
Stata的新估计命令xtmlogit可使用面板多项逻辑(MNL)模型,以对随时间推移观察到的分类结果进行分类。假设我们手机了几个星期关于个人对餐馆选择的数据。餐馆的选择是没有自然排序的分类结果,因此我们可以使用现有的mlogit命令(带有聚类稳健的标准误)。但是xtmlogit直接对单个特征建模,因此可能会产生更有效的结果。并且它可以很好地解释可能与协变量相关的特征。
14. 零膨胀排序逻辑模型
新的估计命令ziologit适合零膨胀排序逻辑回归模型。这个模型是在当数据在最低类别中的观测值比例高于标准有序逻辑模型的预期值时使用的。我们将最低类别中的观测值称为零,因为它们通常对应于某一行为或特征的缺失。零膨胀是通过假设零同时来自逻辑模型和有序逻辑模型来解释的。每个模型可以具有不同的协变量,并且结果可以显示为优势比而不是默认系数。
15. 贝叶斯多层次模型:非线性、联合、类SEM等
您可以使用bayesmh命令的新的精美随机效果语法来拟合贝叶斯多级模型的广度。您可以更轻松地拟合单变量线性和非线性多级模型。现在,您可以拟合多元线性和非线性多级模型!考虑增长线性和非线性多级模型,联合纵向和生存时间模型,SEM型模型等等。
16. 贝叶斯动态预测
在拟合多元时间序列模型(例如向量自回归(VAR)模型)之外,动态预测是一种常见的预测工具。拟合经典var模型后,可以使用fcast计算动态预测。 使用bayes:var拟合贝叶斯var模型后,现在可以使用bayesfcast 来计算贝叶斯动态预测。贝叶斯动态预测会生成整个预测值样本,而不是像传统分析中那样生成单个预测。该样本可用于解答各种建模问题,例如,在估计预测不确定性时,在不做出渐近正态性假设的前提下,该模型对未来观测的预测程度如何。这对于可能会出现渐近正态性假设的小型数据集尤其有吸引力。
17. 贝叶斯IRF与FEVD分析
脉冲响应函数(IRF),动态乘数函数和预测误差方差分解(FEVD)通常用于描述多元时间序列模型(例如VAR模型)的结果。VAR模型具有许多参数,可能难以逐个解释。 IRFs和其他函数将多个参数的影响合并为一个摘要(每个时间段)。例如,IRFs测量一个变量对给定结果变量的冲击(变化)的影响。贝叶斯IRFs(和其他函数)使用IRFs的“精确”后验分布产生结果,这不依赖于渐近正态性的假设。它们还可以为小型数据集提供更稳定的估计,因为它们合并了有关模型参数的先验信息。
18. 使用 BIC 选择Lasso惩罚参数
惩罚参数的选择是lasso分析的基础。套用少量的惩罚可能会包含太多变量。套用较大的惩罚可能会忽略潜在的重要变量。lasso估计已经提供了几种惩罚选择方法,包括交叉验证,自适应和插件。现在,您可以使用贝叶斯信息准则(BIC)通过指定selection(bic)选项在Lasso进行预测和Lasso进行推理之后选择惩罚参数。同样,在拟合Lasso模型后,新的后估计命令bicplot将BIC值绘制为惩罚参数的函数。这为惩罚参数的值提供了方便的图形表示形式,从而使BIC功能最小化。
19. lasso聚类数据
现在,您可以在Lasso分析中解释集群数据。忽略聚类可能会导致错误结果,因为同一聚类中的观测值之间存在相关性。使用Lasso命令进行Lasso和Elasticnet等预测,您可以指定新的cluster({\ it clustvar})选项。使用Lasso命令进行推断(例如:poregress),您可以指定新的vce(cluster {\ it clustvar})选项。
20. 贝叶斯线性和非线性DSGE模型
现在,可以通过在dsge和dsgenl前面加上前缀Bayes:来拟合贝叶斯线性和非线性动态随机一般均衡(DSGE)模型。通过从30多种不同的先验分布中进行选择,合并有关模型参数范围的信息。执行贝叶斯IRF分析,执行区间假设检验,使用贝叶斯因子比较模型等等。
21. Jupyter Notebook与Stata
Jupyter Notebook是一个功能强大且易于使用的Web应用程序,它允许您将在单个文档(“笔记本”)中将可执行代码、可视化、数学方程式和公式、叙述文本以及其他富媒体组合在一起,以进行交互式计算和开发。 它已被研究人员和科学家广泛使用,以分享他们的想法和成果,进行协作和创新。
在Stata 17中,作为PyStat的一部分,您可以使用IPython(交互式Python)内核从Jupyter Notebook调用Stata和Mata。这意味着您可以在一个环境中结合使用Python和Stata的功能,以使您的工作易于复制和与他人共享。
从Jupyter Notebook调用Stata是由新的pystata Python软件包驱动的。
22. 日期和时间的新功能
Stata 17增加了新的便利功能,用于处理Stata和Mata中的日期和时间。 新功能可以分为三类:
1.Datetime持续时间:旨在获取持续时间的函数(例如ages)。
2.相对日期:基于其他日期返回日期的函数,例如相对于给定日期的下一个生日。
3.Datetime组件:从日期时间值中提取不同成分的函数。
新功能将闰年,闰日和闰秒(如果适用的话)考虑在内。
闰秒是一秒的调整,偶尔会应用于协调世界时(UTC)。
23. Intel数学内核库(MKL)
Stata 17引入了在兼容硬件(所有基于Intel和AMD的64位计算机)上使用Intel Math Kernel Library(MKL)的方法,并提供了深度优化的LAPACK例程。
LAPACK是线性代数包的缩写,它是一套用于求解联立方程组、特征值问题和奇值问题等的程序。Mata运算符和函数(如qrd()、lud()和cholesky())在可能的情况下利用LAPACK进行许多数值操作。
由英特尔MKL支持的LAPACK提供了最新的LAPACK例程,这些例程针对现代Intel和现代AMD处理器使用的64位Intel x86-64指令集进行了优化。使用MKL的Mata函数和运算符在性能方面大有裨益。最重要的是,您无需采取任何措施即可充分利用速度的提高。使用这些Mata函数和运算符的Stata命令以及Mata函数和运算符本身,将在兼容硬件上自动使用Intel MKL。
24. Stata on Apple Silicon
Stata 17 for Mac是一款通用应用程序,可以在Apple Silicon和Intel处理器的Mac上运行。采用Apple Silicon的Mac电脑包括新款MacBook Air、MacBook Pro和Mac mini,均采用M1处理器。M1芯片承诺有更高的性能和更大的功能效率。这对于我们的Stata-for-Mac用户来说是值得注意的,他们中的许多人使用Mac笔记本电脑。
虽然第一套M1 mac被认为是入门级的,但我们发现,本机运行Stata的M1 mac比英特尔mac的性能要好30-35%。它们的性能甚至远远超过价格超过两倍的Intel Mac!对于只坚持在其Apple Silicon Mac上使用Apple-Siliconnative软件的用户,从安装程序到应用程序本身,Stata 17的任何部分都不需要用到Rosetta 2。
无论您是在M1 Mac上还是在Intel Mac上本地运行Stata,Stata的功能都相同,并且M1 Mac不需要特殊的许可证。英特尔Mac用户应注意,未来几年,我们将继续支持并发布适用于英特尔处理器的Mac的新版本Stata。
25. JDBC
将Stata与数据库连接变得更加容易了。Stata 17添加了对JDBC(Java数据库连接)的支持。 新的jdbc命令支持JDBC标准,用于与具有矩形数据的关系数据库或非关系数据库管理系统交换数据。您可以从一些最受欢迎的数据库供应商中导入数据,例如Oracle,MySQL,Amazon Redshift,Snowflake,Microsoft SQL Server等。
jdbc的优点在于它是一个跨平台的解决方案,因此我们的JDBC设置适用于Windows,Mac和Unix系统。如果您的数据库供应商提供了JDBC驱动程序,则可以下载并安装该驱动程序,然后通过jdbc在数据库上读取,写入和执行SQL。 您可以将整个数据库表加载到Stata中,也可以使用SQL SELECT将表中的特定列加载到Stata中。您还可以将所有变量插入数据库表中,或仅插入数据集的子集。
26. Java集成
在Stata 17中,您现在可以直接在Stata中嵌入和执行Java代码。您可以在以前的Stata版本中创建和使用Java插件,但这需要您编译代码并将其打包到Jar文件中。在do文件中执行Java可以让您自由地执行直接与Stata代码绑定的Java代码。现在,您可以在do-file或ado-file中编写Java代码,甚至可以从Stata中交互式地调用Java(如JShell)。
Java的优势之一在于与Java虚拟机打包在一起的广泛的APIs。还有许多有用的第三方库。根据您需要执行的操作,您甚至可以编写并行代码以利用多核运算。您编写的Java代码可以即时编译,无需使用外部编译器!此外,还包括Stata函数接口(SFI)Java软件包,提供了Stata与Java之间的双向连接。
SFI包具有访问Stata当前数据集,帧,宏,标量,矩阵,值标签,特征,全局Mata矩阵,日期和时间值等的类。Stata将Java开发工具包(JDK)与其安装捆绑在一起,因此不涉及其他设置。
27. H2O集成
在Stata 17中,我们一直在尝试连接H2O,H2O是一种可扩展的分布式开源机器学习和预测分析平台。您可以在https://docs.h2o.ai/上了解有关H2O的更多信息。
借助H2O的集成,您可以从Stata上启动,连接和查询H2O集群。此外,我们提供了一组命令来处理集群上的数据(H2O帧)。例如,您可以通过导入数据文件或加载Stata的当前数据集来创建新的H2O框架。您还可以在Stata内部拆分,组合和查询H2O帧。尽管对于我们来说,这仍处于试验阶段,但我们希望将其提供给我们的用户进行试用。
另一方面,由于它是实验性功能,因此语法和功能可能会发生变化。使用提供对H2O特定功能的访问的Stata命令时,请记住这是H2O功能。尽管您可能通过Stata命令访问它,但它的工作取决于H2O,并且不在Stata范围内。
28. do文件编辑器:导航,增强书签…
Stata 17中的“文件”编辑器进行了以下改进:
1. 书签:现在与do文件一起保存。
2. 新的导航控件:可以轻松浏览do文件。
3. 语法高亮显示支持现已包括Java和XML。
4. 选区中引号,括号和方括号的自动补全。 例如,选择文本mymacro,然后输入左引号`;。 然后,文件编辑器将用单引号将文本选择绑定,将选择更改为“ mymacro”。
书签:do文件编辑器最需要的功能之一是能够将书签保存在do文件中。书签用于标记感兴趣的行,以便以后更轻松地导航到它们。书签在浏览长do文件时特别有用。 您可以将书签添加到您的do文件的各个部分,以执行数据管理,显示摘要、统计信息并执行统计分析。然后,您可以使用菜单、工具栏或新的导航控件在这些部分之间快速来回移动,而无需滚动几行代码来查找所需的部分。
导航: Stata 17通过新的导航控件使do文件的导航更加容易,该控件显示书签及其标签的列表。从导航控件中选择一个书签会将“do文件编辑器”移至书签所在的行。除了书签之外,导航控件还将显示do文件中的程序列表。从导航控件中选择一个程序会将“do文件编辑器”移至该程序的释义。无需将其他程序添加到“导航”中。 DO文件编辑器将自动将程序的释义添加到导航控件中。
29. 非参数的趋势检验
现在,nptrend命令支持四种跨有序组的趋势检验。您可以在the Cochran–Armitage test, the Jonckheere–Terpstra test, the linear-by-linear trend test, and the Cuzick test using ranks之间进行选择。前三个检验是新的,而第四个检验由nptrend先前执行。
Stata17破解版软件功能
1、双重差分法的官方命令
“双重差分法”(Difference-in-differences,简记DID)或许是最常用的计量方法。怎么能没有DID的Stata官方命令呢?为此,Stata 17及时地推出了DID的官方命令xtdidregress;其中,“xt” 表示这是适用于面板数据的命令。
除了进行常规的 DID 估计,命令xtdidregress还允许最多指定三个“分组变量”(group variables),或两个分组变量与一个时间变量,从而进行“三重差分法”(Difference-in-differences-in-differences,简记DDD)的估计。
另外,针对“重复截面数据”(repeated cross-sectional data),即所谓“准面板”(pseudo panel data),Stata 17也推出了相关的新命令didregress,可进行类似 DID 的估计。更重要的是,你可以用DID的官方命令,轻松地画平行趋势图啦~
2、完美的表格输出
实证研究者经常需要将Stata的多个回归结果以表格形式输出到word文件中。虽然早有官方命令estimates table可完成此类任务,但比较死板;故此前Stata用户一般使用非官方命令(比如estout或outreg)来输出回归结果。为此,Stata 17大幅改善了原来的table命令,使用户可轻松地以表格形式汇报回归结果(regression results)或统计特征(summary statistics)。
进一步,你可以设计回归表格的风格(styles),并应用于所创建的表格,然后将此表格输出到Word或其他形式的文件(包括PDF、HTML、LaTex、Excel、markdown 等)。另外,你还可以使用新增的前缀(prefix)collect,来收集Stata命令的各种估计结果。最后,Stata 17还新增了Table Builder(表格创建器),让用户可通过点击鼠标(point-and-click)来创建表格。
3、Lasso的新功能
作为“高维回归”(high-dimensional regression)的常用工具,Stata 16已经推出了有关Lasso(Least Absolute Shrinkage and Selection Operator,即所谓 “套索估计量”)的一系列官方命令。Stata 17则提供了更多有关 Lasso 的新功能。
使用Lasso估计处理效应模型。在 Stata 16 中,可使用命令teffects估计“处理效应”(treatment effects)模型;而命令lasso则用于估计协变量很多的高维模型。Stata 17则将二者结合起来,其推出的新命令telasso,可估计包含很多协变量的处理效应模型。
使用 BIC 选择Lasso惩罚参数。作为一种“惩罚回归”(penalized regression),在进行Lasso估计时,需要选择惩罚参数(penalty parameter)。在Stata 16中,可使用交叉验证(cross-validation)、适应性方法(adaptive method)或代入法(plugin)来选择惩罚参数。
在Stata 17中,新增了选择项 “selection(bic)”,可使用 “贝叶斯信息准则”(Bayesian Information Criterion,简记BIC)选择惩罚参数。而且,新增的估计后命令(postestimation command)bicplot 可以很方便地将此选择过程可视化。
使用Lasso处理聚类数据。对于“聚类数据”(cluster data),由于每个聚类中观测值存在自相关,故通常的Lasso估计可能导致偏差。在Stata 17中,在使用命令lasso或elasticnet时,可通过新增选择项 “cluster(clustvar)” 来处理聚类数据。进一步,对于使用Lasso进行统计推断的命令,比如poregress(表示partialing-out regress),则可使用Stata 17的新增选择项 “cluster(clustvar)” 来得到聚类稳健的标准误(cluster-robust standard errors)。
4、离散选择模型的新命令
离散选择模型(discrete choice model)是微观计量经济学的常用模型。在Stata 17中,增加了以下离散选择模型的新命令:
“面板多项逻辑模型”(panel multinomial logit model)。对于横截面数据的多项逻辑模型,Stata已有mlogit命令。Stata 17新增的xtmlogit命令则可使用面板数据估计多项逻辑模型。这无疑是Stata在离散选择模型方面的一大进步,因为此前Stata只能使用xtlogit或xtprobit估计面板二值选择模型。
“零膨胀排序逻辑模型”(zero-inflated ordered logit model)。对于排序数据(ordered data),此前可使用Stata命令ologit或oprobit进行估计。在实践中,有时排序数据中最低类别所占比重很大。若将最低类别的取值记为“零”,则存在所谓“零膨胀”现象。此时可使用Stata 17的新增命令ziologit,估计更有效率的“零膨胀排序逻辑模型”(zero-inflated ordered logit model)。
5、久期数据的新命令
“久期数据”(duration data)常用于生物统计的 “生存分析”(survival analysis),在经济学中也有广泛用途,例如失业的持续时间,婚姻的延续时长,王朝的寿命等。久期数据常存在 “删失”(censoring)或 “归并” 问题,比如当研究结束时,有些病人可能尚未死亡;或者有些失业者还未找到工作。
Stata 17新推出的命令stintcox,可使用Cox模型来估计一种特殊的“区间删失”(interval-censored)数据。对于区间删失数据,我们只知道事件发生于某个区间,但无法确知其发生时点;比如,只知道癌症复发于两次体检之间的时段。如果忽略久期数据存在的区间删失问题,则会导致估计偏差。
6、贝叶斯计量经济学的全面升级
在大数据时代,由于数据日益复杂而多样,在处理有些问题时,基于频率学派的传统计量方法可能不便使用,使得贝叶斯学派的计量经济学逐渐兴起。频率学派认为待估计的参数是给定的未知数(fixed unknown parameters),而贝叶斯学派则将未知参数视为服从某个分布的随机变量,并可随时根据新的样本信息将其 “先验分布”(prior distribution)更新为 “后验分布”(posterior distribution)。Stata 17将Stata中原有的贝叶斯统计学与计量经济学进行了全面升级。
贝叶斯面板数据模型(Bayesian panel-data models)。Stata目前已有的面板命令包括xtreg(静态面板),xtlogit或xtprobit(面板二值选择模型),以及xtologit或xtoprobit(面板排序模型)等。在 Stata 17中,如果要使用贝叶斯方法估计这些面板模型,只要在原命令之前加上 “前缀”(prefix)bayes即可。
贝叶斯向量自回归模型(Bayesian VAR models)。“向量自回归”(Vector Autoregression,简记VAR)是常见的时间序列模型。在已有的Stata中,可用命令var来估计VAR模型,而后续命令则包括:使用fcast进行 “动态预测”(dynamic forecast),以及使用irf估计 “脉冲响应函数”(impulse response function,简记 IRF)与 “预测误差方差分解”(forecast error variance decomposition,简记 FEVD)。
在Stata 17中,则可使用命令“bayes: var”(即在命令var之前加上前缀 bayes)估计贝叶斯的 VAR 模型,然后用bayesfcast进行动态预测;而脉冲响应函数与预测误差方差分解也可类似地得到。
然后,使用bayesfcast进行动态预测;
而脉冲响应函数(IRF)与预测误差方差分解(FEVD)也可类似地得到。
使用贝叶斯方法估计VAR模型有两大好处。首先,VAR模型通常包含较多参数,若样本较小,则估计结果不稳定。而贝叶斯方法由于较易“整合先验信息”(incorporating prior information),故在用小样本估计VAR模型时更为稳健。
其次,经典的VAR模型使用大样本理论进行统计推断与预测,需要假设估计量服从渐近正态分布,在小样本中不易满足。而贝叶斯方法则不使用大样本理论,也无须渐近正态的假设,故更适用于小样本。
贝叶斯多层模型(Bayesian multilevel models)。Stata 17新推出的bayesmh命令可以估计一系列的贝叶斯多层模型,包含“单变量”(univariate)或“多变量”(multivariate)的线性与非线性多层模型(linear and nonlinear multilevel models),乃至面板的生存时间模型(joint longitudinal and survival-time models)以及结构方程之类的模型(SEM-type models)等。
贝叶斯线性与非线性DSGE模型(Bayesian linear and nonlinear DSGE models)。“动态随机一般均衡”(Dynamic Stochastic General Equilibrium,简记DSGE)模型是宏观经济学的主流模型。在Stata 16 中,可使用命令dsge与dsgenl分别估计线性与非线性的 DSGE 模型。
在Stata 17中,只要在命令dsge与dsgenl之前加上前缀bayes,即可估计相应的线性或非线性的贝叶斯DSGE模型。可供用户选用的 “先验分布”(prior distribution)多达30以上,并可进行贝叶斯脉冲响应分析(Bayesian IRF analysis),区间假设检验(interval hypothesis testing),以及使用贝叶斯因子(Bayesian factors)来比较模型等。
7、非参数的趋势检验
有时样本数据中存在分组(比如,分为3组),且这些分组有天然的排序(比如,记为1,2,3组),即所谓 “排序分组”(ordered groups)。在这种排序分组的数据中,经常希望检验某个变量在此分组排序中(比如,第1-3组),是否存在某种趋势,比如此变量的取值倾向于越来越大,即所谓 “tests for trend across ordered group”。
为此,可使用Stata已有命令nptrend,进行非参数的Cuzick秩检验(Cuzick test using ranks)。而Stata 17的最新版nptrend命令,则在 Cuzick秩检验之外,新增了三个非参数检验,即“Cochran-Armitage test”,“Jonckheere-Terpstra test” 与“linear-by-linear trend test”,使得命令nptrend的功能大大增强。
8、元分析的新命令
“元分析”(meta-analysis)将多个类似的研究结果综合在一起。比如,针对某个疫苗的有效性(vaccine efficacy),在世界各地进行了多个实验,如何将每个实验所得的疫苗有效性指标,通过加权平均得到统一的度量。Stata 17将Stata的元分析功能作了进一步的提升。
多维元分析(Multivariate meta-analysis)。在将多个研究结果综合在一起时,其中的每个研究可能同时汇报 “多个效应规模”(multiple effect sizes),而这些效应之间可能存在相关性。若使用Stata既有的 meta命令,则会忽略这种相关性。Stata 17的新增命令meta mvregress可进行多维元分析,并处理这种相关性。
加尔布雷斯图(Galbraith plots)。Stata 17还新增了命令meta galbraithplot,可以画元分析的 “加尔布雷斯图”(Galbraith plots)。此图可用于评估不同研究之间的异质性(assessing heterogeneity of the studies),并发现潜在的极端值(potential outliers)。
留一元分析(Leave-one-out meta analysis)。Stata 17新增了 “留一元分析”(Leave-one-out meta-analysis)的功能。所谓“留一元分析”,就是在进行元分析时,每次均留出一个研究(不放在样本中),以考察元分析结果的稳健性;比如,最终结果是否过度依赖于某个研究。在使用Stata命令meta summarize或meta forestplot进行元分析时,可使用新增的选择项leaveoneout来进行留一元分析。
9、Stata与Python、Java、H2O及Jupyter Notebook的整合
在大数据时代,Stata也在加快与主流软件平台的整合,为用户提供更多的增值服务。这在Stata 17的此次升级中体现尤其突出。
与 Python 的整合(Python integration)。Python已是炙手可热的主流计算机语言。为此,Stata 16专门提供了一个与Python的接口,让用户在熟悉的Stata界面下调用Python,并在Stata中显示运行结果。Stata 17则更进一步,推出了新的Python包(Python package)pystata,使得用户可在Python 中方便地调用Stata。Stata 17还引入了一个新概念 “PyStata” ,包括 Stata与Python交互的所有方式。
与 Java 的整合(Java integration)。Java是一种应用广泛的跨平台编程语言。在Stata 17中,你可以十分方便地在Stata程序中嵌入并执行 Java 代码。
对于JDBC数据交换格式的支持(Support for JDBC)。JDBC(Java Database Connectivity)是一个在不同程序与数据库之间交换数据的跨平台标准(a cross-platform standard for exchanging data between programs and databases)。在Stata 17中,通过支持JDBC,使得 Stata用户可从一些最流行的数据库导入数据,包括Oracle、MySQL、AmazonRedShift、Snowflake、Microsoft SQL Server等。
与H2O的整合(H2O integration)。H2O是一款流行的机器学习软件平台。在Stata 17中,你可以连接并调用H2O的机器学习算法。这无疑为Stata用户打开了另外一扇通往机器学习的窗口!
在Jupyter Notebook中使用Stata(Jupyter Notebook with Stata)。Jupyter Notebook是一款基于网页的流行“集成开发环境”(integrated development environment,简记 IDE),尤其方便展示代码、公式、文字与可视化。在Stata 17中,作为PyStata的一部分(依赖于 Python 包 pystata),你可以从 Jupyter Notebook调用 Stata与Mata(Stata的矩阵语言)。这意味着,你可以在同一环境中整合Python与Stata的功能,使得你的工作更加可复制(reproducible)且易于分享。
10、Do文件编辑器的改进与Stata速度提升等
Do文件编辑器的改进(Do-file Editor improvements)。随着编程的重要性日益提高,Stata 16在Do文件编辑器中加入了 “自动填写完成”(autocompletion)与 “语法高亮”(syntax highlighting)的功能。Stata 17又将Do文件编辑器的功能进一步提升。
在Stata 17的Do文件编辑器中,可通过设置 “bookmarks”(书签)而在一个较长的do文件中迅速跳至想要编辑的部分。Stata 17的Do文件编辑器还新增了“navigation control”(导航),其中罗列所有的书签及其标签(bookmarks and their labels),以该Do文件中的全部“程序”(programs)。
Stata的速度提升(Faster Stata)。在大数据时代,基础算法的速度越来越重要。为此,Stata 17更新了命令sort与collapse的算法,使之更为快捷。另外,Stata 17也提升了命令mixed(用于估计多层混合效应模型,即 multilevel mixed-effects models)的运行速度。
使用Intel Math Kernel Library(MKL)提升速度。Stata 17引入了Intel Math Kernel Library(MKL),适用于所有Intel或AMD的64位计算机,从而可调用深度优化(deeply optimized)的LAPACK(Linear Algebra PACKage)线性代数包。这将使得Stata与Mata的底层计算速度进一步提升,而Stata用户无须作任何事情即可享用。
处理日期与时间的新函数(New functions for dates and times)。Stata 17 引入了方便处理日期与时间的新函数,包括Datetime duration(计算持续时间),Datetime relative dates(计算相对日期,比如下个生日的日期),以及Datetime(从日期中提取不同的成分)。这些新函数还会自动考虑闰年(leap years)、闰日(leap days)与闰秒(leap seconds)的因素。
总之,Stata 17是一次令人激动的重大升级,不仅有贝叶斯计量经济学的高歌猛进,与主流计算机语言平台的深度整合,更便于编程的Do文件编辑器,而且更为贴近计量实战的需求(DID,表格输出,离散选择等)。显然,在可预见的将来,Stata 依然会是经管社科的首选计量与统计软件。









- 精选留言 来自广西贵港移动用户 发表于: 2023-11-27
- 费劲千辛万苦终于让我找到这个了,很棒
- 精选留言 来自重庆重庆移动用户 发表于: 2023-3-20
- 这款软件我说NB没有毛病吧!
- 精选留言 来自山东济南电信用户 发表于: 2023-5-9
- 试试看,回头再来反馈
- 精选留言 来自山东临沂移动用户 发表于: 2023-3-2
- 创新十足,喜欢
- 精选留言 来自甘肃平凉移动用户 发表于: 2023-12-10
- 试下看看,下下来看看好不好用的。
- 第1楼 来自安徽省安庆市联通用户 发表于2025-03-31
- 厉害,真的很不错,非常nice!
盖楼(回复)
































 浙公网安备 33038202002266号
浙公网安备 33038202002266号